

Accès à des Publications de Qualité
L’accès à des revues scientifiques de haut niveau, à des articles de qualité et à des bases de données spécialisées est essentiel.
Données Complètes et à Jour
Les chercheurs et experts de la R&D ont besoin de données exhaustives et à jour.
Outils de Traitement et d'Analyse
Des outils avancés d’analyse des données et de traitement de l’information sont nécessaires pour extraire des tendances, des modèles et des informations significatives à partir d’ensembles de données complexes.
Interopérabilité des Données
La possibilité d’intégrer et de faire interagir différents ensembles de données est cruciale pour obtenir une vue d’ensemble et favoriser la collaboration entre les domaines.
Veille Technologique et Scientifique
La capacité de suivre les avancées technologiques et scientifiques dans leur domaine d’expertise est essentielle.
Fiabilité des Sources
Les experts recherchent des informations auprès de sources fiables et réputées pour garantir l’exactitude et la fiabilité des données.
Recherche Documentaire
Les systèmes d’IA permettent une recherche documentaire, triant rapidement d’énormes volumes de documents scientifiques pour fournir aux chercheurs des informations pertinentes et à jour.
La base de donnée d’Opscidia contient plus de 180 Millions de documents scientifiques (Brevets, articles scientifiques, revues…) mise à jour quotidiennement.
Analyse de Données massives
L’IA excelle dans l’analyse de grandes quantités de données, extrayant rapidement des modèles et des tendances pour informer les décisions en R&D.
Sur des documents scientifiques, l’analyse de données massive va permettre de gagner énormément de temps dans la sélection et l’analyse du bon document scientifique.
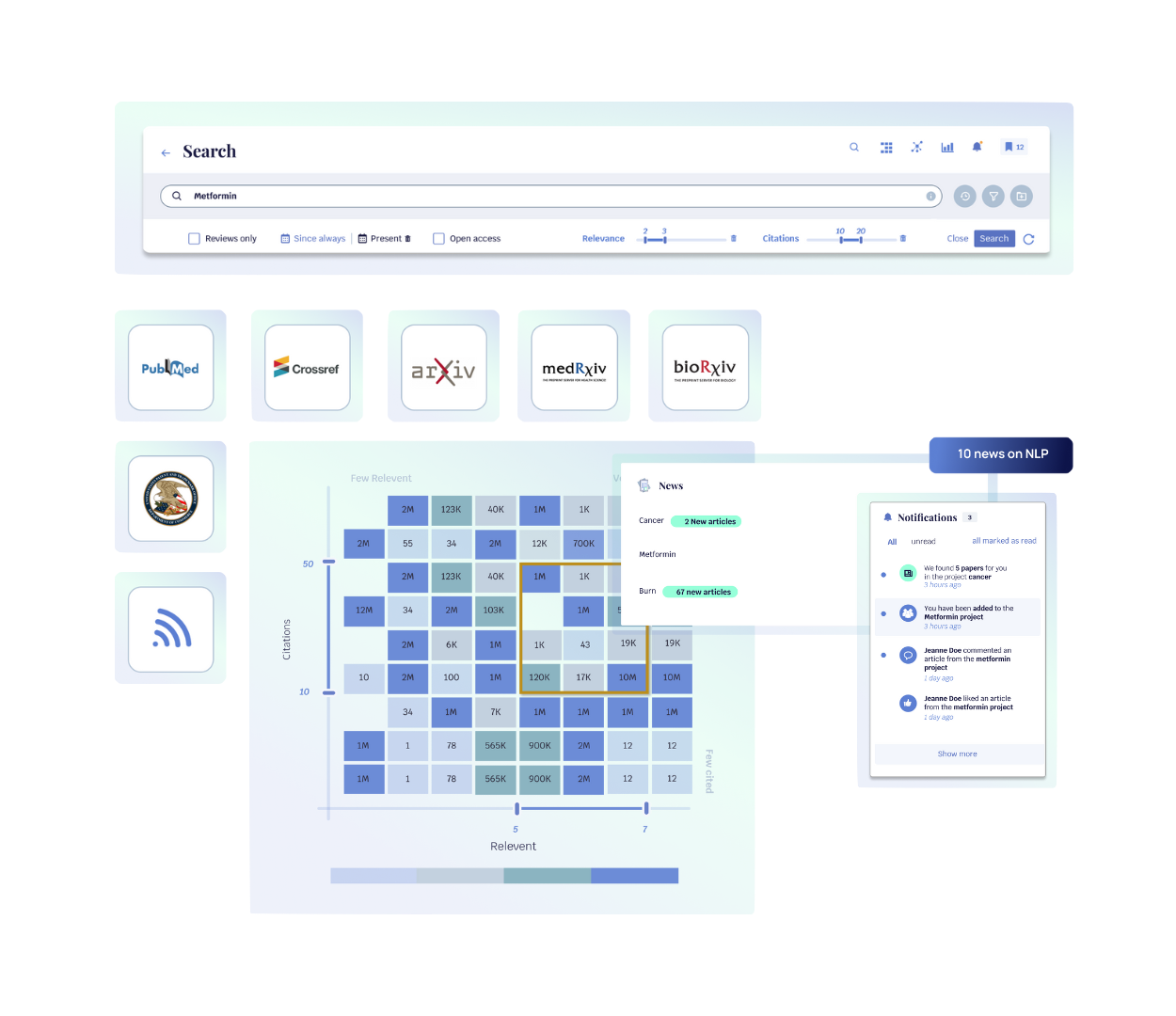
Découverte de Modèles et de Tendances
Les algorithmes d’IA peuvent aider à découvrir des modèles ou des tendances dans les données, ce qui peut être particulièrement utile pour identifier des relations non évidentes dans des ensembles de données complexes.
Avec l’App Opscidia, surveillez les écosystèmes de domaines scientifiques. Décelez des relations cachées entre des concepts scientifiques et comparez les flux de publications scientifiques des termes de votre choix.
Prévision et Surveillance
L’IA peut être utilisée pour prévoir des événements naturels, surveiller des écosystèmes, et contribuer à la gestion durable des ressources naturelles.
l’App Opscidia a une fonctionnalité spécialement dédiée à la surveillance d’écosystème scientifique.