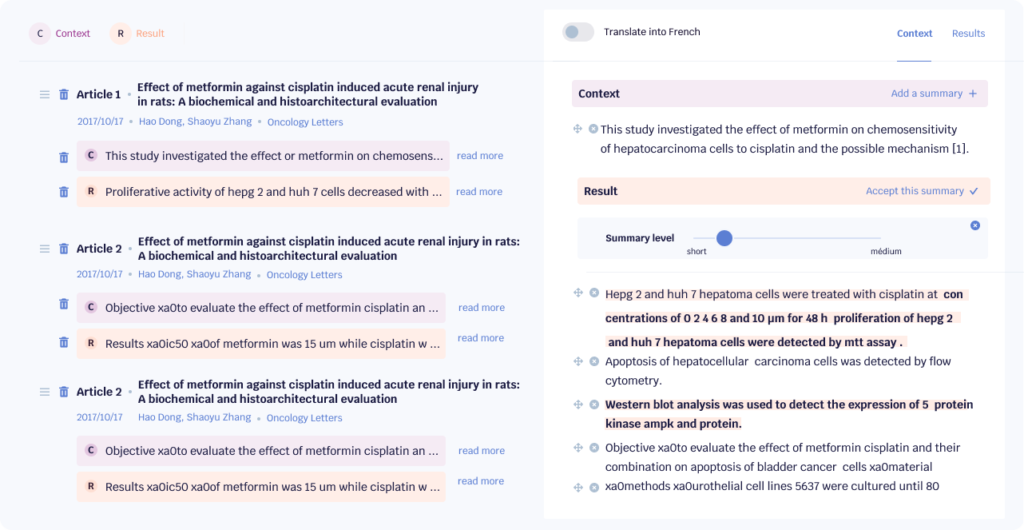
Les réseaux de neurones et le développement des applications de reconnaissance des images
D’habitude chez Opscidia, on parle beaucoup de texte. Aujourd’hui, on va changer un peu et on va parler d’images. Pourquoi ? L’analyse automatique d’image repose sur les mêmes technologies (les réseaux de neurones) que l’analyse automatique de texte. Ce domaine a quelques années d’avance sur l’analyse automatique de texte, donc nous l’avons beaucoup regardé pour nous en inspirer. On vous propose donc de vous partager un peu de ce que nous avons appris !
La reconnaissance d’images est un domaine en constante évolution, qui a connu de nombreuses avancées ces dernières années grâce au développement de l’intelligence artificielle et des réseaux de neurones. En effet, les réseaux de neurones sont des algorithmes de machine learning qui sont particulièrement adaptés à la reconnaissance d’images, car ils peuvent apprendre à reconnaître des patterns complexes à partir de données d’entraînement.
- Qu’est-ce qu’un réseau de neurones et comment reconnaît-il des images ?
- L’évolution des réseaux de neurones pour reconnaissance des images dans le temps.
- Les avantages et les inconvénients d’utilisation de réseau de neurones pour la reconnaissance d’image
- Les différents défis à surmonter dans les développements d’applications pour la reconnaissance d’image
- Des exemples d’utilisation de réseau de neurones pour la reconnaissance d’image
Qu’est-ce qu’un réseau de neurones et comment reconnaît-il des images ?
Un réseau de neurones est constitué de couches de neurones connectés entre eux, qui sont entraînés à traiter des données d’entrée et à produire des résultats précis. Pour la reconnaissance d’images, les données d’entrée sont des images pixelisées, et les résultats sont des labels prédits pour chaque image. Par exemple, un réseau de neurones peut être entraîné à reconnaître des chiens dans des images, et lorsqu’il reçoit une nouvelle image en entrée, il prédit si cette image contient un chien ou non.
Il existe différents types de réseaux de neurones qui peuvent être utilisés pour la reconnaissance d’images, mais le plus connu est le réseau de neurones convolutionnel (CNN). Les CNNs sont particulièrement adaptés à la reconnaissance d’images, car ils sont conçus pour traiter des données qui ont une structure spatiale, comme les images. Les CNNs sont formés de couches de neurones qui sont conçues pour extraire des caractéristiques de l’image, comme des lignes ou des formes, et pour les combiner pour prédire un label.
L’évolution des réseaux de neurones dans le temps.
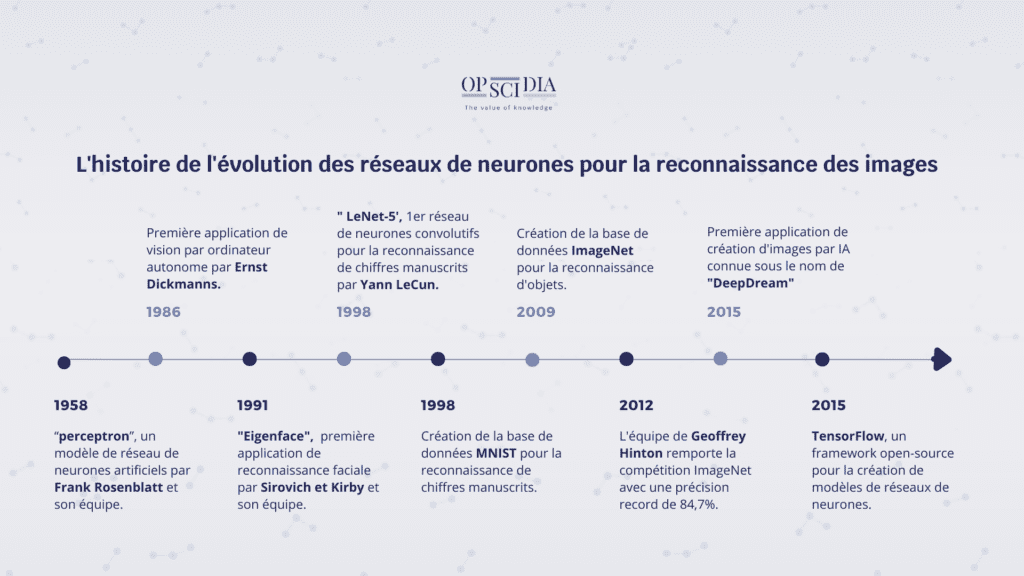
Frise chronologique : l’évolution des réseaux de neurones pour la reconnaissance des images.
Les réseaux de neurones artificiels ont été développés dans les années 1950, mais leur utilisation dans la reconnaissance d’images n’a réellement commencé qu’à la fin des années 1980.
1958 : L’ingénieur en électronique Frank Rosenblatt développe le premier “perceptron”, un modèle de réseau de neurones artificiels”
1986 : Ernst Dickmanns et son équipe à l’Université de la Bundeswehr Munich en Allemagne ont développé la première application de vision par ordinateur autonome. Ils ont développé un système de vision par ordinateur pour permettre à une voiture de se déplacer de manière autonome. Le système utilisait des caméras vidéo pour capturer des images de la route et des algorithmes de traitement d’images pour identifier les obstacles et calculer la trajectoire optimale pour la voiture.
1991: La première application de reconnaissance faciale s’appelle « Eigenface » et a été développée en 1991 par Sirovich et Kirby et utilisé par Matthew Turk et Alex Pentland pour la classification de visages. Cependant, il s’agissait d’une application de reconnaissance faciale basée sur des techniques d’analyse de composantes principales plutôt que sur les réseaux de neurones utilisés aujourd’hui.
1998 : Yann LeCun et ses collègues de l’Université de New York développent LeNet-5, un modèle de réseau de neurones convolutifs pour la reconnaissance de chiffres manuscrits.
Yann LeCun a développé les réseaux de neurones convolutifs (ConvNets) pour reconnaître des chiffres manuscrits sur des chèques pour le département de recherche AT&T Bell Labs. Dans les années 1990, la reconnaissance d’images avec des ConvNets a stagné en raison du manque de données d’entraînement et de la puissance de calcul limitée des ordinateurs de l’époque.
1998 : Création de la base de données MNIST pour la reconnaissance de chiffres manuscrits
2009 : Création de la base de données ImageNet pour la reconnaissance d’objets.
Ces bases de données ont permis aux chercheurs de collecter et d’annoter des images en grand nombre, permettant ainsi d’entraîner des réseaux de neurones plus complexes.
2012 : L’équipe de recherche de Geoffrey Hinton de l’Université de Toronto utilise une architecture de réseau de neurones appelée “Réseau de neurones à convolution profonde” (Deep Convolutional Neural Network – DCNN) pour remporter la compétition ImageNet avec une précision record de 84,7%.
Cette victoire a marqué le début d’une nouvelle ère pour la reconnaissance d’images, où les réseaux de neurones ont commencé à dépasser les performances des algorithmes classiques dans de nombreuses tâches de vision par ordinateur.
2015 : Google présente TensorFlow, un framework open-source pour la création de modèles de réseaux de neurones, qui permettra de faciliter l’entrainement et l’utilisation des modèles de réseaux de neurones.
2015 : La première application de création d’images par IA connue sous le nom de « DeepDream » a été développée par Alexander Mordvintsev en 2015 chez Google. DeepDream utilise des réseaux de neurones convolutifs pour générer des images originales à partir d’une image source donnée.
Les avantages d’utilisation de réseau de neurones pour la reconnaissance d’image.
Il y a plusieurs avantages à utiliser des réseaux de neurones pour la reconnaissance d’images. Tout d’abord, ils sont capables de traiter des images de haute résolution et de reconnaître des patterns complexes qui seraient difficiles à détecter pour un humain. Ensuite, ils sont capables d’apprendre de manière autonome à partir de données d’entraînement, ce qui signifie qu’ils peuvent s’adapter à de nouvelles images sans avoir besoin de programmation explicite. Enfin, ils sont souvent plus rapides et plus précis que les approches de reconnaissance d’images traditionnelles, comme les classificateurs basés sur les caractéristiques.
Les défis à surmonter dans les développements d’applications pour la reconnaissance d’image.
Il y a cependant quelques défis à surmonter dans le développement d’applications de reconnaissance d’images basées sur des réseaux de neurones. Tout d’abord, ils nécessitent souvent une quantité importante de données d’entraînement pour obtenir une performance satisfaisante. Si vous n’avez pas suffisamment de données d’entraînement, votre modèle pourrait ne pas être assez robuste pour généraliser de nouvelles images. Deuxièmement, ils peuvent être coûteux à entraîner, en particulier si vous utilisez un GPU (processeur graphique) pour accélérer le processus. Enfin, ils peuvent être difficiles à comprendre et à interpréter, ce qui peut être un défi pour certaines applications qui nécessitent une explication des prédictions.
Malgré ces défis, la reconnaissance d’images par réseaux de neurones reste une technologie très prometteuse, qui est utilisée dans de nombreuses applications, notamment la santé, la sécurité, la publicité et les loisirs. Elle ouvre la voie à de nouvelles possibilités de traitement de l’information visuelle et à de meilleures expériences utilisateur dans de nombreux domaines.
Des exemples d’utilisation de réseau de neurones pour la reconnaissance d’image
- DALL-E pas Open IA : DALL-E est un programme d’intelligence artificielle qui génère des images à partir de descriptions textuelles. Il s’appuie sur une version du modèle GPT-3 comprenant 12 milliards de paramètres pour interpréter les entrées et produire les images demandées. Les objets créés peuvent être aussi bien réalistes que non existants, par exemple une chèvre en haut du mont blanc, Un hybride entre un hippopotame et une poule ou bien une voiture du futur…
- Text to Art par MidJourney : Le générateur d’art « Text-to-Art » basés sur l’IA permettent de créer des images réalistes ou artistiques à partir d’un texte. Ces systèmes sont alimentés par des modèles d’intelligence artificielle avancés dotés de milliards de paramètres et entraînés sur des milliards d’images.
- La reconnaissance faciale est une technologie biométrique qui utilise des algorithmes de type « deep learning »en cartographiant les caractéristiques du visage humain afin de créer une empreinte faciale. Ces modèles sont entrainés sur un grand nombre d’images d’humain présentes sur le web, puis le système de reconnaissances facial repère et compare les caractéristiques du visage pour identifier une personne à partir d’une image. En France, seule la reconnaissance faciale par la police et la gendarmerie est autorisée à travers le TAJ (traitement d’antécédents judiciaires). Cette base contient 18 millions de personnes dont 8 millions avec photos. La reconnaissance faciale permet donc aux forces policières françaises de retrouver des individus enregistrés au TAJ grâce à des images ou des vidéos capturées, par exemple lors des manifestations publiques. La reconnaissance faciale en temps réel n’est pas permise par les lois françaises.
En résumé, les réseaux de neurones sont un outil puissant pour la reconnaissance d’images, qui ont connu de nombreuses avancées ces dernières années grâce à l’intelligence artificielle. Ils sont particulièrement adaptés à la reconnaissance de patterns complexes dans des images de haute résolution, et sont utilisés dans de nombreuses applications pour améliorer les expériences utilisateur. Cependant, ils nécessitent une quantité importante de données d’entraînement et peuvent être coûteux à entraîner, et peuvent être difficiles à comprendre et à interpréter. Malgré ces défis, ils restent une technologie très prometteuse qui ouvre la voie à de nouvelles possibilités de traitement de l’information visuelle.
En savoir plus
Aller au chapitre
Découvrez comment Opscidia résout les problèmes de veille technologique.