Facial Recognition
Masked Face Recognition and Privacy Protection in Authentication Systems
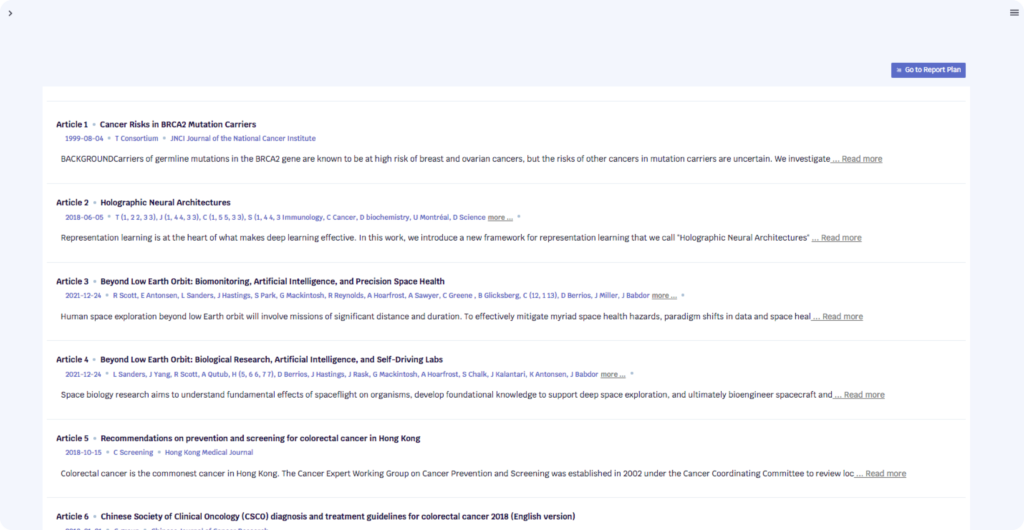
Masked face recognition and privacy protection in authentication systems is a crucial area of research. With the advancement of facial recognition technology and the increasing use of face recognition in various domains such as casino management systems, smart home environments, and event venues, the need to address the challenges related to recognizing masked faces and ensuring privacy protection has become imperative [1] [3] [5] .
Facial recognition systems are being used in networked casino management computer systems to identify players based on their facial images and record their activities [1] . In smart home environments, electronic greeting systems with facial recognition capabilities are employed to detect and respond to visitors approaching the entryway [3] . Event venues utilize facial recognition to capture event occurrences and the reactions of eventgoers, enabling the identification of specific individuals in photos or videos [5] .
These applications highlight the need to address the issues of recognizing masked faces, as masks can hinder accurate facial recognition. Additionally, privacy concerns arise with the use of facial recognition technology, especially in public spaces. The methods proposed in these studies aim to tackle these challenges.
In the casino management system, the facial recognition system accesses a biometric database to match the received facial image, while the casino management server identifies the player record and records the activity of the associated device [1] . The smart home environment’s electronic greeting system initiates facial recognition while the visitor approaches the entryway and incorporates context information from sensors to determine an appropriate response [3] . Event venues use facial recognition to identify eventgoers in photos or videos captured during event occurrences and send personalized content to the identified individuals [5] .
The use of facial recognition technology in various domains presents both opportunities and challenges. While it enhances security and convenience, recognizing masked faces and safeguarding privacy are important considerations. The research discussed in these articles addresses these concerns by proposing methods to improve masked face recognition and protect privacy in authentication systems. Further advancements in this field will contribute to the development of more efficient and secure authentication systems.
Facial Recognition for Enhanced Security and Authentication
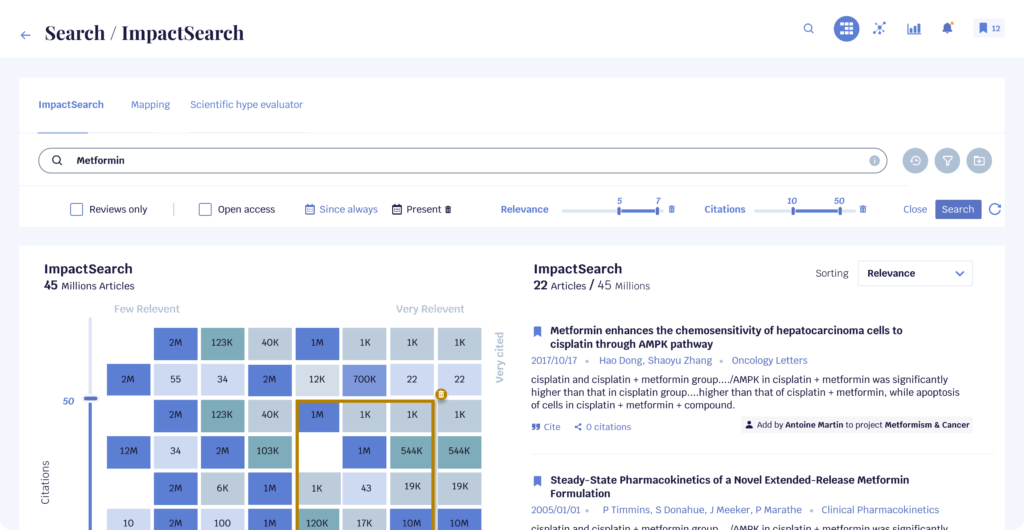
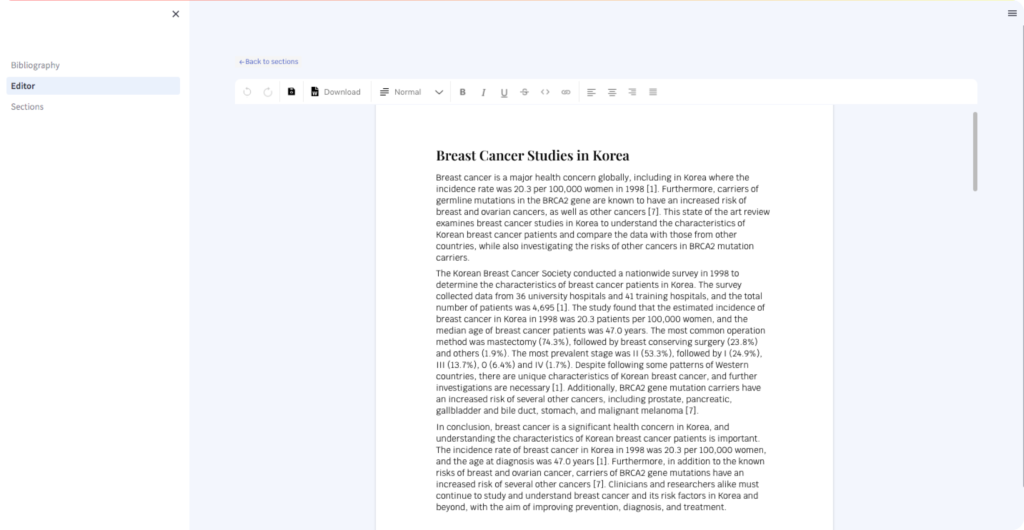
Facial recognition technology has become increasingly prevalent in various applications, such as authentication and attendance tracking. However, the use of face masks due to the COVID-19 pandemic has posed a challenge to the accuracy of these systems. This paper aims to address this issue by proposing a methodology that incorporates masked faces into existing facial datasets, allowing for accurate recognition without the need for recreating user datasets. The proposed approach includes an open-source tool called MaskTheFace, which effectively masks faces and generates a large dataset of masked faces. This dataset is then used to train a facial recognition system that demonstrates improved accuracy for masked faces.
The use of face masks as a preventive measure during the COVID-19 pandemic has raised concerns regarding the accuracy of facial recognition systems used for authentication and attendance tracking [2] . Due to the obstruction caused by face masks, these systems may fail to detect and recognize individuals, rendering existing datasets invalid and rendering the facial recognition systems inoperable. To address this issue, the paper presents a methodology that utilizes the current facial datasets by augmenting them with tools that enable the recognition of masked faces with low false-positive rates and high overall accuracy, without requiring the recreation of user datasets [2] .
The paper introduces an open-source tool called MaskTheFace, which is designed to effectively mask faces and generate a large dataset of masked faces. This tool enables the training of a facial recognition system specifically tailored for recognizing masked faces. The effectiveness of the proposed methodology is demonstrated by reporting an increase of 38% in the true positive rate for the Facenet system [2] .
To further validate the accuracy of the retrained system, the paper conducts tests on a custom real-world dataset called MFR2. The results show similar levels of accuracy, confirming the effectiveness of the methodology [2] .
In conclusion, the paper addresses the challenge posed by face masks on facial recognition systems by proposing a methodology that incorporates masked faces into existing datasets. By using the MaskTheFace tool to generate a large dataset of masked faces and retraining the facial recognition system, the accuracy for recognizing masked faces improves significantly. This approach allows for the utilization of existing datasets without the need for recreating user datasets, ensuring the continued operability of facial recognition systems in the presence of face masks [2] .
In conclusion, the paper presents a methodology to overcome the accuracy challenge faced by facial recognition systems due to the use of face masks. The proposed approach incorporates masked faces into existing datasets, allowing for accurate recognition without the need for recreating user datasets. By utilizing the open-source tool MaskTheFace to generate a dataset of masked faces and retraining the facial recognition system, significant improvements in accuracy are achieved. The methodology is validated through experiments, reporting an increase in the true positive rate of the Facenet system and demonstrating similar levels of accuracy on a real-world dataset. Overall, the proposed methodology provides a practical solution for maintaining the operability of facial recognition systems in the presence of face masks [2] .
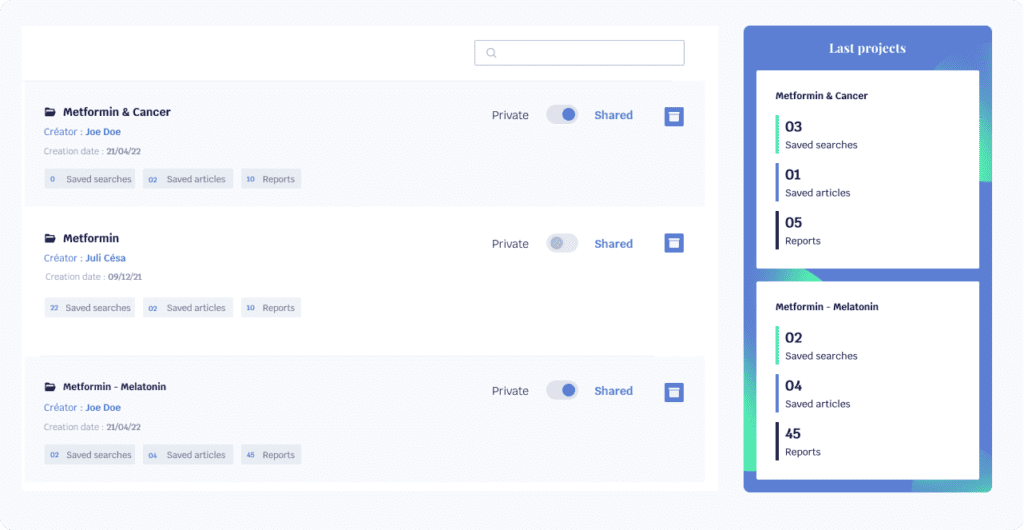
References
1 Edward, S., Jason, B., Jeffrey, G., & Thomas, S. E.. (2022). Casino management system with a patron facial recognition system and methods of operating same. . https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/11455864
2 Andrew, R., David, P., & Hartwig, A.. (2019). Facial recognition with social network aiding. . https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/10515114
3 Christopher, B. Charles, Haerim, J., Jason, G. Evans, James, S. Edward, Jeffrey, B. A., Michael, D., Rajeev, N., Rengarajan, A., Sahana, M., Sayed, S. Yusef, Seungho, Y., & Yu-An, L.. (2020). Systems and methods of detecting and responding to a visitor to a smart home environment. . https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/10664688
4 Aqeel, A., & Arijit, R.. (2020). Masked Face Recognition for Secure Authentication. . 10.48550/arxiv.2008.11104
5 Gene, F., John, C., Nick, R., & Seth, C. Melvin. (2019). Facial recognition for event venue cameras. . https://image-ppubs.uspto.gov/dirsearch-public/print/downloadPdf/10264175